El ácido desoxirribonucleico,
abreviado como ADN, es un ácido nucleico que contiene instrucciones genéticas usadas en el desarrollo y
funcionamiento de todos los organismos vivos conocidos y algunos virus, y es responsable de su transmisión hereditaria.
El papel principal de la molécula de ADN es el almacenamiento a largo plazo
de información. Muchas veces, el ADN es comparado
con un plano o una receta, o un código, ya que contiene las instrucciones
necesarias para construir otros componentes de las células, como las proteínas y las moléculas de ARN.
Los segmentos de ADN que llevan esta información genética son llamados genes, pero las otras secuencias de ADN
tienen propósitos estructurales o toman parte en la regulación del uso de esta
información genética.
Para que la información que contiene el ADN
pueda ser utilizada por la maquinaria celular, debe copiarse en primer lugar en
unos trenes de nucleótidos, más cortos y con unas unidades diferentes,
llamados ARN. Las moléculas de ARN se copian exactamente del
ADN mediante un proceso denominado transcripción. Una vez procesadas en el núcleo celular,
las moléculas de ARN pueden salir al citoplasma para su utilización posterior.
La información contenida en el ARN se interpreta usando el código genético,
que especifica la secuencia de los aminoácidos de las proteínas, según una
correspondencia de un triplete de nucleótidos (codón) para cada aminoácido.
Esto es, la información genética
(esencialmente: qué proteínas se van a producir en cada momento del ciclo
de vida de una célula) se halla codificada en las secuencias de nucleótidos del
ADN y debe traducirse para poder funcionar. Tal traducción se realiza usando el
código genético a modo de diccionario. Por ejemplo, en el caso de la secuencia
de ADN indicada antes (ATGCTAGATCGC...), la ARN polimerasa utilizaría
como molde la cadena complementaria de dicha secuencia de ADN (que
sería TAC-GAT-CTA-GCG-...) para transcribir una molécula de ARN que se
leería AUG-CUA-GAU-CGC-.
Estructura
química del ADN: dos cadenas de
nucleótidos conectadas mediante puentes de hidrógeno, que aparecen como
líneas punteadas.
El ADN es un largo polímero formado por unidades repetitivas,
los nucleótidos. Una doble cadena de ADN mide de 22 a 26 angstroms (2,2 a 2,6 nanómetros) de ancho, y una unidad (un nucleótido) mide
3,3 Å (0,33 nm) de largo. Aunque cada unidad
individual que se repite es muy pequeña, los polímeros de ADN pueden ser moléculas enormes que contienen millones de nucleótidos. Por ejemplo, el cromosoma humano más largo,
el cromosoma número 1, tiene aproximadamente 220 millones
depares de bases.
En los organismos vivos, el ADN no suele existir como una
molécula individual, sino como una pareja de moléculas estrechamente asociadas.
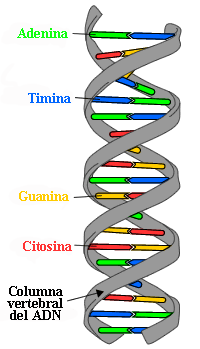
Las dos cadenas de ADN se enroscan sobre sí mismas
formando una especie de escalera de caracol, denominada doble hélice.
Componentes
• Ácido fosfórico:
Enlace fosfodiéster. El grupo fosfato (PO43-) une
el carbono 5' del azúcar de un nucleósido con el carbono 3' del siguiente.
Su fórmula química es H3PO4. Cada nucleótido puede contener uno (monofosfato: AMP), dos (difosfato: ADP) o tres (trifosfato: ATP) grupos de ácido fosfórico, aunque como
monómeros constituyentes de los ácidos nucleicos sólo aparecen en forma de nucleósidos
monofosfato.
• Desoxirribosa:
Es un monosacárido de 5 átomos de carbono (una pentosa) derivado de la ribosa, que forma parte de la estructura de
nucleótidos del ADN. Su fórmula es C5H10O4. Una de las principales diferencias
entre el ADN y el ARN es el azúcar, pues en el ARN la 2-desoxirribosa del ADN es reemplazada por una pentosa alternativa, la ribosa.
Las moléculas de azúcar se unen entre sí a
través de grupos fosfato, que forman enlaces fosfodiéster entre los átomos de carbono
tercero (3′, «tres prima») y quinto (5′, «cinco prima») de dos anillos
adyacentes de azúcar.
Bases nitrogenadas:
Las cuatro bases nitrogenadas mayoritarias que
se encuentran en el ADN son la adenina (A), la citosina (C), la guanina (G) y la timina (T). Cada una de estas cuatro
bases está unida al armazón de azúcar-fosfato a través del azúcar para formar
el nucleótido completo (base-azúcar-fosfato).
Timina:
En el código genético se representa con la
letra T. Es un derivado pirimidínico con un grupo oxo en
las posiciones 2 y 4, y un grupo metil en la posición 5. Forma el nucleósido timidina (siempre
desoxitimidina, ya que sólo aparece en el ADN) y el nucleótido timidilato o timidina
monofosfato (dTMP).
• Citosina:
En el código genético se representa con la
letra C. Es un derivado pirimidínico, con un grupo amino en
posición 4 y un grupo oxo en posición 2. Forma el nucleósido citidina (desoxicitidina
en el ADN) y el nucleótido citidilato o
(desoxi)citidina monofosfato (dCMP en el ADN, CMP en el ARN).
• Guanina:
En el código genético se representa con la
letra G. Es un derivado púrico con un grupo oxo en la posición 6 y un
grupo amino en la posición 2. Forma el nucleósido (desoxi)guanosina y el
nucleótido guanilato o
(desoxi) guanosina monofosfato (dGMP, GMP).
http://www.sesbe.org/evosite/evo101/IIIC2ReviewDNA.shtml.html
http://www.sesbe.org/evosite/evo101/IIIC2ReviewDNA.shtml.html

http://genemol.org/biomolespa/la-molecula-de-adn/molecula-ADN.html
No hay comentarios:
Publicar un comentario